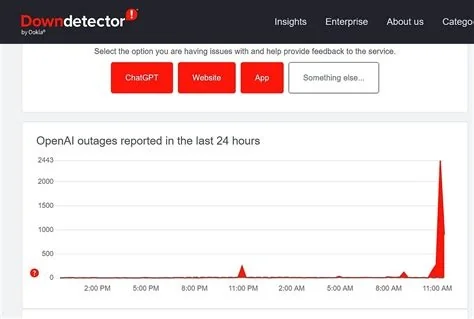
Downdetector has flagged recent outages that hit Outlook, OpenAI’s ChatGPT, and Microsoft’s broader cloud suite, confirming a global disruption across these core services. The alerts show thousands of users reporting login failures, delayed responses, and service latency, underscoring how essential real‑time monitoring is for both individuals and enterprises that rely on these platforms.
Outlook Outage Details
Two days ago the Outlook dashboard on Downdetector spiked with “Can’t log in” and “Can’t send e‑mail” reports. Users across multiple time zones saw the same red‑flag icon, indicating a worldwide issue rather than a regional glitch. The live map highlighted a global impact, though Microsoft has not disclosed a specific cause.
Impact on Users
- Missed calendar invites and meeting reminders.
- Stalled sales pipelines and delayed client communications.
- Increased support tickets and internal troubleshooting time.
ChatGPT Service Disruptions
Within the same week, Downdetector recorded two separate surges of complaints about ChatGPT. The first incident lasted about an hour, while the second stretched into a second day, peaking at roughly 24,000 reports. Developers, content creators, and educators all felt the slowdown, questioning the reliability of the AI platform.
Frequency and Scale
- First glitch: brief, lasted ~1 hour, triggered a wave of user frustration.
- Second glitch: extended over 24 hours, generated tens of thousands of alerts.
- Both events highlight that even cutting‑edge AI services can experience brief, recurring hiccups.
Why Monitoring Matters
Real‑time monitoring tools like Downdetector give you an early warning signal before official status pages update. By aggregating user reports, social mentions, and automated pings, the platform creates an “outage index” that many IT teams and journalists now reference as a first‑hand indicator of service health.
Using Multiple Sources
Relying on a single source can lead to false alarms. The best practice is to triangulate data: check Downdetector for a quick pulse, then verify with the provider’s official status dashboard, social‑media updates, and internal telemetry. This approach helps you confirm issues faster and reduces unnecessary panic.
Best Practices for Users and IT Teams
If you’re an individual user, start by refreshing the service, clearing caches, and checking Downdetector for a broader view. For IT professionals, integrate outage signals into your monitoring stack, update incident‑response playbooks, and establish clear communication channels to inform stakeholders promptly.
- Quick Check: Look up the service on Downdetector.
- Confirm: Verify with the official status page.
- Escalate: Trigger internal alerts if thresholds are exceeded.
In the end, outages are inevitable, but detecting them early, communicating clearly, and recovering swiftly can keep productivity on track. Downdetector may not fix the problem, but it sure helps you see it coming.