
Z.ai’s new GLM‑5 large‑language‑model architecture slashes energy consumption by roughly 40 % per token, delivering the same performance while dramatically cutting power bills. By leveraging a mixture‑of‑experts design, the model reduces joules‑per‑token during inference, letting data‑center operators run more queries on the same hardware and stay within tighter PUE limits for your workloads.
Why Energy Efficiency Matters for LLM Inference
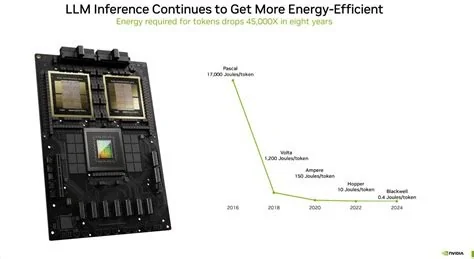
Inference now accounts for the bulk of an LLM’s lifecycle power draw, often exceeding 80 % of total energy use. Every token you generate consumes electricity, so a 40 % reduction translates directly into lower operating costs and a smaller carbon footprint. The savings add up quickly when millions of queries hit a chatbot each day.
Impact on AI Chip Design
Chip makers are responding by building “power‑capped” GPUs and purpose‑built AI accelerators that can enforce strict joule budgets without throttling performance. These silicon upgrades let you squeeze more work out of each rack while keeping power‑usage‑effectiveness (PUE) within acceptable limits.
New Chip Families Targeting Lower Joules‑Per‑Token
Recent releases from leading vendors feature higher throughput per watt, with architectures that prioritize energy‑aware scheduling. By dynamically adjusting voltage and clock speeds, these chips maintain latency targets even as they operate under tighter power caps.
Open‑Source Models Join the Efficiency Race
Community‑driven LLMs such as Llama 3, Mistral, Qwen and DeepSeek are now publishing joules‑per‑token metrics alongside accuracy scores. This shift encourages developers to optimize for both performance and power, making greener AI a realistic goal for a broader range of applications.
Talent Demand in Energy‑Aware AI
Companies that blend AI with energy‑intensive domains—like grid balancing or renewable‑energy forecasting—are actively hiring engineers who understand both machine‑learning algorithms and hardware power constraints. The convergence of these skill sets is becoming a top hiring priority.
Practical Steps for Enterprises
To stay cost‑efficient at scale, organizations should integrate observability tools that track joules‑per‑token, enforce power caps at the inference layer, and automate workload placement onto the most efficient nodes. The result is lower OPEX, higher hardware utilization, and a clearer path toward sustainability certifications.
Practitioner Insight
“We’ve been tracking joules‑per‑token since the first guidelines appeared, and the GLM‑5 numbers are the first real proof point that MoE designs can deliver the promised energy savings,” says Maya Patel, senior infrastructure engineer at a cloud‑AI provider. “Our team is already re‑architecting the scheduler to prioritize power‑capped GPUs, which lets us keep latency under control while staying within a tighter PUE budget.”
Looking Ahead: The Future of Efficient AI Chips
Upcoming silicon will likely leverage dynamic voltage scaling, advanced memory technologies, and tighter integration with software schedulers. As you plan for the next generation of AI workloads, expect the industry to favor models and chips that can do more with less power, turning energy efficiency from a nice‑to‑have feature into a hard requirement.


